Redshift
Introduction
Section titled “Introduction”RedShift is a cloud-based data warehouse solution which allows end users to aggregate huge volumes of data and parallel processing of data. RedShift is fully managed by AWS and serves as a petabyte-scale service which allows users to create visualization reports and critically analyze collected data. The query results can be saved to an S3 Data Lake while additional analytics can be provided by Athena or SageMaker.
LocalStack allows you to use the RedShift APIs in your local environment to analyze structured and semi-structured data across local data warehouses and data lakes. The supported APIs are available on the API coverage section for Redshift and Redshift Data, which provides information on the extent of RedShift’s integration with LocalStack.
Getting started
Section titled “Getting started”This guide is designed for users new to RedShift and assumes basic knowledge of the AWS CLI and our awslocal wrapper script.
Start your LocalStack container using your preferred method. We will demonstrate how to create a RedShift cluster and database while using a Glue Crawler to populate the metadata store with the schema of the RedShift database tables using the AWS CLI.
Define the variables
Section titled “Define the variables”First, we will define the variables we will use throughout this guide. Export the following variables in your shell:
REDSHIFT_CLUSTER_IDENTIFIER="redshiftcluster"REDSHIFT_SCHEMA_NAME="public"REDSHIFT_DATABASE_NAME="db1"REDSHIFT_TABLE_NAME="sales"REDSHIFT_USERNAME="crawlertestredshiftusername"REDSHIFT_PASSWORD="crawlertestredshiftpassword"GLUE_DATABASE_NAME="gluedb"GLUE_CONNECTION_NAME="glueconnection"GLUE_CRAWLER_NAME="gluecrawler"The above variables will be used to create a RedShift cluster, database, table, and user. You will also create a Glue database, connection, and crawler to populate the Glue Data Catalog with the schema of the RedShift database tables.
Create a RedShift cluster and database
Section titled “Create a RedShift cluster and database”You can create a RedShift cluster using the CreateCluster API.
The following command will create a RedShift cluster with the variables defined above:
awslocal redshift create-cluster \ --cluster-identifier $REDSHIFT_CLUSTER_IDENTIFIER \ --db-name $REDSHIFT_DATABASE_NAME \ --master-username $REDSHIFT_USERNAME \ --master-user-password $REDSHIFT_PASSWORD \ --node-type n1You can fetch the status of the cluster using the DescribeClusters API.
Run the following command to extract the URL of the cluster:
REDSHIFT_URL=$(awslocal redshift describe-clusters \ --cluster-identifier $REDSHIFT_CLUSTER_IDENTIFIER | jq -r '(.Clusters[0].Endpoint.Address) + ":" + (.Clusters[0].Endpoint.Port|tostring)')Create a Glue database, connection, and crawler
Section titled “Create a Glue database, connection, and crawler”You can create a Glue database using the CreateDatabase API.
The following command will create a Glue database:
awslocal glue create-database \ --database-input "{\"Name\": \"$GLUE_DATABASE_NAME\"}"You can create a connection to the RedShift cluster using the CreateConnection API.
The following command will create a Glue connection with the RedShift cluster:
awslocal glue create-connection \ --connection-input "{\"Name\":\"$GLUE_CONNECTION_NAME\", \"ConnectionType\": \"JDBC\", \"ConnectionProperties\": {\"USERNAME\": \"$REDSHIFT_USERNAME\", \"PASSWORD\": \"$REDSHIFT_PASSWORD\", \"JDBC_CONNECTION_URL\": \"jdbc:redshift://$REDSHIFT_URL/$REDSHIFT_DATABASE_NAME\"}}"Finally, you can create a Glue crawler using the CreateCrawler API.
The following command will create a Glue crawler:
awslocal glue create-crawler \ --name $GLUE_CRAWLER_NAME \ --database-name $GLUE_DATABASE_NAME \ --targets "{\"JdbcTargets\": [{\"ConnectionName\": \"$GLUE_CONNECTION_NAME\", \"Path\": \"$REDSHIFT_DATABASE_NAME/%/$REDSHIFT_TABLE_NAME\"}]}" \ --role r1Create table in RedShift
Section titled “Create table in RedShift”You can create a table in RedShift using the CreateTable API.
The following command will create a table in RedShift:
REDSHIFT_STATEMENT_ID=$(awslocal redshift-data execute-statement \ --cluster-identifier $REDSHIFT_CLUSTER_IDENTIFIER \ --database $REDSHIFT_DATABASE_NAME \ --sql \ "create table $REDSHIFT_TABLE_NAME(salesid integer not null, listid integer not null, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp)" | jq -r .Id)You can check the status of the statement using the DescribeStatement API.
The following command will check the status of the statement:
wait "awslocal redshift-data describe-statement \ --id $REDSHIFT_STATEMENT_ID" ".Status" "FINISHED"Run the crawler
Section titled “Run the crawler”You can run the crawler using the StartCrawler API.
The following command will run the crawler:
awslocal glue start-crawler \ --name $GLUE_CRAWLER_NAMEYou can wait for the crawler to finish using the GetCrawler API.
The following command will wait for the crawler to finish:
wait "awslocal glue get-crawler \ --name $GLUE_CRAWLER_NAME" ".Crawler.State" "READY"You can finally retrieve the schema of the table using the GetTable API.
The following command will retrieve the schema of the table:
awslocal glue get-table \ --database-name $GLUE_DATABASE_NAME \ --name "${REDSHIFT_DATABASE_NAME}_${REDSHIFT_SCHEMA_NAME}_${REDSHIFT_TABLE_NAME}"Resource Browser
Section titled “Resource Browser”The LocalStack Web Application provides a Resource Browser for managing RedShift clusters. You can access the Resource Browser by opening the LocalStack Web Application in your browser, navigating to the Resources section, and then clicking on RedShift under the Analytics section.
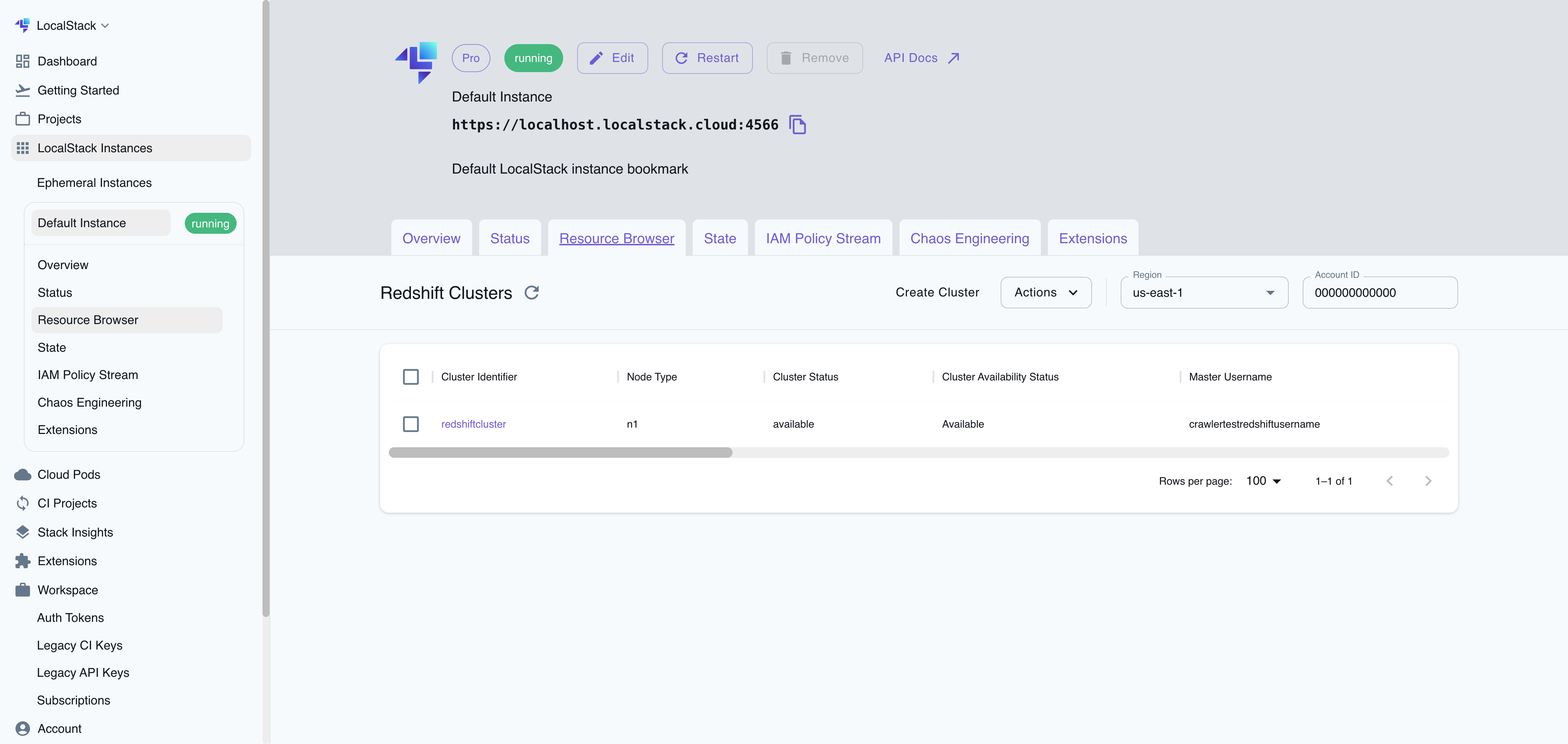
The Resource Browser allows you to perform the following actions:
- Create Cluster: Create a new RedShift cluster by specifying the cluster identifier, database name, master username, master password, and node type.
- View Cluster: View the details of a RedShift cluster, including the cluster identifier, database name, master username, master password, node type, and endpoint.
- Edit Cluster: Edit an existing RedShift cluster by clicking the cluster name and clicking the EDIT CLUSTER button.
- Remove Cluster: Remove an existing Redshift cluster by selecting it from the table and clicking the ACTIONS followed by Remove Selected button.
API Coverage
Section titled “API Coverage”| Operation ▲ | Implemented ▼ | Verified on Kubernetes |
|---|
API Coverage (Redshift Data)
Section titled “API Coverage (Redshift Data)”| Operation ▲ | Implemented ▼ | Verified on Kubernetes |
|---|