Transcribe
Introduction
Section titled “Introduction”Transcribe is a service provided by AWS that offers automatic speech recognition (ASR) capabilities. It enables developers to convert spoken language into written text, making it valuable for a wide range of applications, from transcription services to voice analytics.
LocalStack allows you to use the Transcribe APIs for offline speech-to-text jobs in your local environment. The supported APIs are available on our API Coverage section, which provides information on the extent of Transcribe integration with LocalStack.
LocalStack Transcribe uses an offline speech-to-text library called Vosk. It requires an active internet connection to download the language model. Once the language model is downloaded, subsequent transcriptions for the same language can be performed offline. Language models typically have a size of around 50 MiB and are saved in the cache directory (see Filesystem Layout).
Getting Started
Section titled “Getting Started”This guide is designed for users new to Transcribe and assumes basic knowledge of the AWS CLI and our awslocal wrapper script.
Start your LocalStack container using your preferred method. We will demonstrate how to create a transcription job and view the transcript in an S3 bucket using the AWS CLI.
Create an S3 bucket
Section titled “Create an S3 bucket”You can create an S3 bucket using the mb command.
Run the following command to create a bucket named foo to upload a sample audio file named example.wav:
awslocal s3 mb s3://fooawslocal s3 cp ~/example.wav s3://foo/example.wavCreate a transcription job
Section titled “Create a transcription job”You can create a transcription job using the StartTranscriptionJob API.
Run the following command to create a transcription job named example for the audio file example.wav:
awslocal transcribe start-transcription-job \ --transcription-job-name example \ --media MediaFileUri=s3://foo/example.wav \ --language-code en-INYou can list the transcription jobs using the ListTranscriptionJobs API.
Run the following command to list the transcription jobs:
awslocal transcribe list-transcription-jobsThe following output would be retrieved:
{ "TranscriptionJobSummaries": [ { "TranscriptionJobName": "example", "CreationTime": "2022-08-17T14:04:39.277000+05:30", "StartTime": "2022-08-17T14:04:39.308000+05:30", "LanguageCode": "en-IN", "TranscriptionJobStatus": "IN_PROGRESS" } ]}View the transcript
Section titled “View the transcript”After the job is complete, the transcript can be retrieved from the S3 bucket using the GetTranscriptionJob API.
Run the following command to get the transcript:
awslocal transcribe get-transcription-job --transcription-job example{ "TranscriptionJob": { "TranscriptionJobName": "example", "TranscriptionJobStatus": "COMPLETED", "LanguageCode": "en-IN", "MediaFormat": "wav", "Media": { "MediaFileUri": "s3://foo/example.wav" }, "Transcript": { "TranscriptFileUri": "s3://foo/7844aaa5.json" }, "CreationTime": "2022-08-17T14:04:39.277000+05:30", "StartTime": "2022-08-17T14:04:39.308000+05:30", "CompletionTime": "2022-08-17T14:04:57.400000+05:30", }}You can then view the transcript by running the following command:
awslocal s3 cp s3://foo/7844aaa5.json .jq .results.transcripts[0].transcript 7844aaa5.jsonThe following output would be retrieved:
"it is just a question of getting rid of the illusion that we are separate from nature"Audio Formats
Section titled “Audio Formats”The following input media formats are supported:
- Adaptive Multi-Rate (AMR)
- Free Lossless Audio Codec (FLAC)
- MPEG-1 Audio Layer-3 (MP3)
- MPEG-4 Part 14 (MP4)
- OGG
- Matroska Video files (MKV)
- Waveform Audio File Format (WAV)
Supported Languages
Section titled “Supported Languages”The following languages and dialects are supported:
| Language | Language Code |
|---|---|
| Catalan | ca-ES |
| Czech | cs-CZ |
| German | de-DE |
| English, British | en-GB |
| English, Indian | en-IN |
| English, US | en-US |
| Spanish | es-ES |
| Farsi | fa-IR |
| French | fr-FR |
| Gujarati | gu-IN |
| Hindi | hi-IN |
| Italian | it-IT |
| Japan | ja-JP |
| Kazakh | kk-KZ |
| Korean | ko-KR |
| Dutch | nl-NL |
| Polish | pl-PL |
| Portuguese | pt-BR |
| Russian | ru-RU |
| Telugu | te-IN |
| Turkish | tr-TR |
| Ukrainian | uk-UA |
| Uzbek | uz-UZ |
| Vietnamese | vi-VN |
| Chinese | zh-CN |
Resource Browser
Section titled “Resource Browser”The LocalStack Web Application provides a Resource Browser for managing Transcribe Transcription Jobs. You can access the Resource Browser by opening the LocalStack Web Application in your browser, navigating to the Resource Browser section, and then clicking on Transcribe Service under the Machine Learning section.
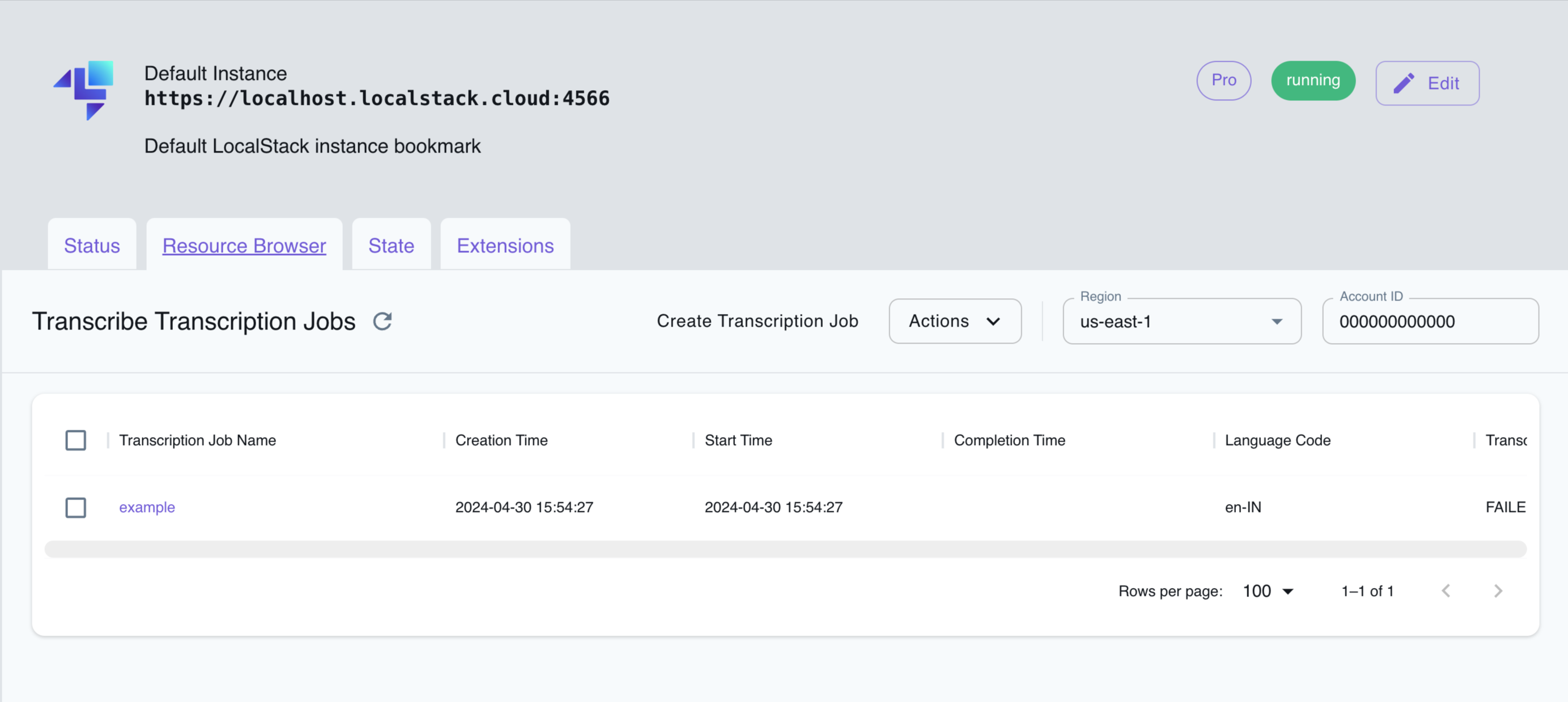
The Resource Browser allows you to perform the following actions:
- Create Transcription Job: Create a new transcription job by clicking on the Create Transcription Job button, and then providing the required details.
- View Transcription Job: View the details of a specific transcription job by clicking on the job in the list.
- Delete Transcription Job: Delete the transcription job by clicking on the Actions button followed by Remove Selected button.
Examples
Section titled “Examples”The following code snippets and sample applications provide practical examples of how to use Transcribe in LocalStack for various use cases:
Limitations
Section titled “Limitations”Transcribe does not support speaker diarization and does not produce certain other numerical information, like confidence levels.
API Coverage
Section titled “API Coverage”| Operation ▲ | Implemented ▼ | Verified on Kubernetes |
|---|